




Compare High Availability vs Fault Tolerance vs Redundancy
If you want to build an IT infrastructure with almost zero downtime, then you may have been confused by the terms High Availability, Fault Tolerance, and Redundancy. means respectively. This article will introduce them respectively, and compare High Availability vs Fault Tolerance vs Redundancy.
By Crystal / Updated on September 16, 2022
High Availability vs Fault Tolerance vs Redundancy?
If you want to build a 24/7 IT infrastructure and disaster recovery plan for your organization, you must have heard of High Availability (HA), Fault Tolerance (FT), and Redundancy. They are 3 terms that are often confused by newcomers to the industry and are often used interchangeably.
On the surface, they all aim to achieve continuity of IT systems. However, in fact, there are also many differences between them. Each of these terms has its specific definition, methodology and role. This article will introduce them respectively and analyze the difference between High Availability vs Fault Tolerance vs Redundancy.

What is High Availability (HA)
High Availability (HA) refers to achieving the maximum uptime of a system by eliminating a single point of failure in that system, ensuring the system’s mission-critical applications and websites remain online nearly always during a catastrophic event.
It is a characteristic of a system, and a concept embodied only by technology. In essence, Redundancy is key to server uptime by establishing a High Availability Hardware Environment. This is accomplished by assigning more than one server and a floating IP address with data replication to keep them in sync as a failover mechanism.
It allows secondary systems to take over in the event of a failure. When one server fails, it triggers the movement of services from the failed primary system to a functioning secondary system to take over, ensuring that traffic continues to flow with minimal disruption.
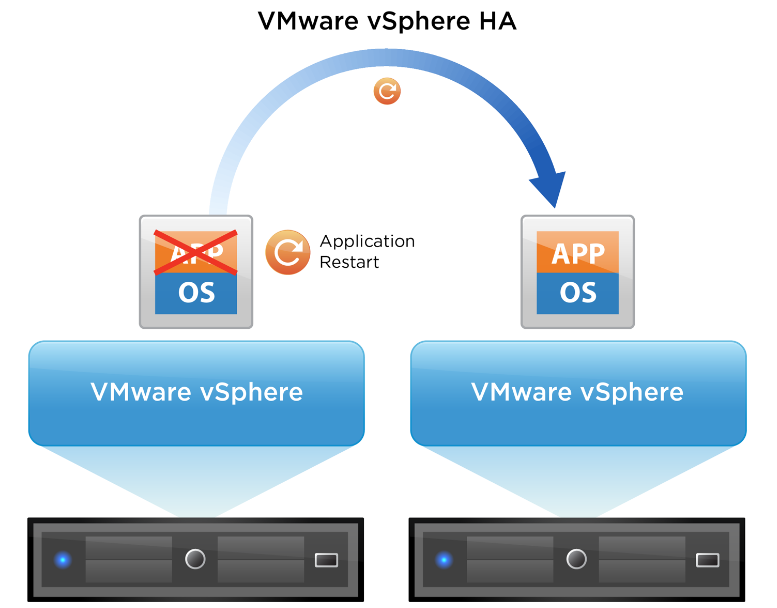
With the help of cluster technology, you can create Highly Availability servers on either Hyper-V or VMware products. For example, a Hyper-V High Availability 2019 server or VMware High Availability cluster.
VMware High Availability features
VMware vSphere is one of the most popular enterprise workload platforms, and it also provide the High Availability infrastructure to deliver availability to applications running in virtual machines independent of the operating system to automatically reduce application downtime.
VMware High Availability is configured on a clustered environment, so having a clear understanding of the cluster, planning for unexpected growth and failure, implementing robust monitoring, and reduce latency between components are the VMware High Availability best practices.
The VMware High Availability features include:
- Monitor VMware vSphere hosts and virtual machines to detect hardware and guest operating system failures.
- Restart virtual machines on other vSphere hosts in the cluster without manual intervention when a server outage is detected.
- Reduce application downtime by automatically restarting virtual machines upon detection of an operating system failure.
What is Fault Tolerance (FT)
Fault Tolerance (FT) refers to the ability of a system to function properly when one or more components fail, or the ability of software to detect and recover from errors in the software or hardware that runs an application. If High Availability still has a fraction of downtime, then Fault Tolerance is guaranteed to be zero downtime.
In essence, Fault Tolerance is a form of redundancy, enabling visitors to access the system in the event of the failure of one or more components.
It is implemented through a storage area network (SAN). Using extremely fast, low-latency Gigabit Ethernet directly attached to servers, a SAN is an extremely scalable and fault-tolerant central networked storage cluster for critical data. Users transfer data sequentially or in parallel without affecting the performance of the host server.
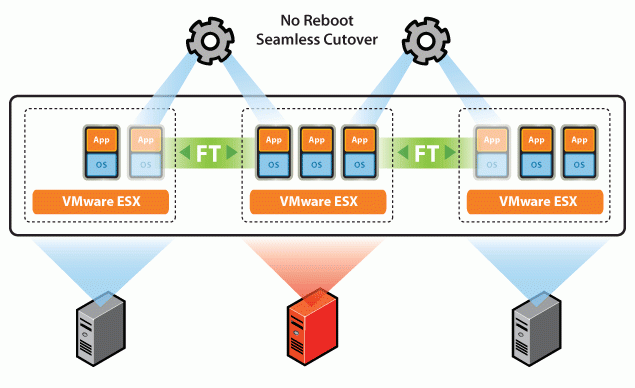
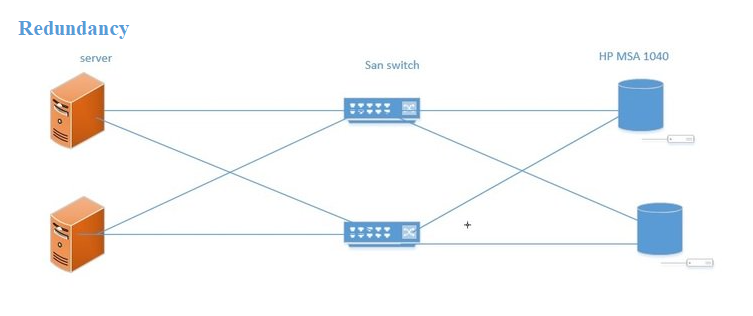
What is Redundancy
Redundancy refers to the duplication of critical components or functions of a system with the intention of increasing reliability of the system, usually in the form of a backup or fail-safe, or to improve actual system performance.
As I mentioned before, Redundancy is the key to build High Availability. It can best be understood as 2 servers with duplicated or mirrored data, excluding failover procedures, focusing only on duplication of hardware and software, specifically explaining how to eliminate hardware or software points of failure.
High Availability vs Fault Tolerance vs Redundancy
Comparing High Availability vs Fault Tolerance vs Redundancy, the redundancy is the basic preparation for High Availability and Fault Tolerance. To conclude, Redundancy is the form of Fault Tolerance, and an essential component of High Availability.
- Comparing High Availability vs Redundancy, HA includes automatic failover in the event of any type of failure, while Redundancy specifically describes how to eliminate hardware or software points of failure.
- Comparing Fault Tolerance vs Redundancy, FT is about ensuring minimal and core business operations stay online, while redundancy is only concerned with duplication of hardware and software.
- Comparing High Availability vs Fault Tolerance, the FT environment has no business interruption but significantly higher costs, while a HA environment has minimal business interruption.
Summary
While they are all important considerations for building a low downtime IT infrastructure, High Availability, Fault Tolerance and Redundancy are 3 terms that can be easily confused. This article introduced them respectively, and compared High Availability vs Fault Tolerance vs Redundancy.
After understanding these 3 terms and their differences, you can choose from them according to your actual needs. They will provide great advantages in minimizing downtime and ensuring business continuity, including in virtualization disaster recovery.

