




What Is Amazon S3 Archive and How to Use It
If you're dabbling in cloud storage and need a way to store massive amounts of data without breaking the bank, you can try Amazon S3 Archive.
By Crystal / Updated on October 30, 2024
What is an S3 archive?
Amazon S3 Archive is for long-term data retention and archiving and is a storage solution within Amazon Simple Storage Service (S3). It utilizes a tiered approach to storage to make it easier for you to decide for yourself how often you want to access your data. At the same time, Amazon S3 Archive is flexible enough to allow you to choose different retrieval options depending on your needs, for example, if you need fast access, you can choose expedited retrieval. Its storage structure not only has the ability to hold massive amounts of data, but also maintains data security and integrity.

Why businesses love Amazon S3 Archive?
It offers a way to offload rarely accessed data without having to pay top dollar. Simply put,
- For starters, it's cost-effective—who doesn't like saving money? When compared to other storage options, S3 Archive is a fraction of the cost, especially if you're storing data for the long haul.
- It's also scalable, meaning you can start with a little and grow into a lot without any headaches.
✍ Tips: Keep in mind that while storage is cheap, frequent data retrieval can add up.
Amazon S3 Glacier vs Amazon S3 Glacier Deep Archive
Amazon S3 (Simple Storage Service) provides a variety of storage classes tailored to different use cases. The primary AWS services designed for archival purposes are Amazon S3 Glacier and Amazon S3 Glacier Deep Archive.
|
|
S3 Glacier |
S3 Glacier Deep Archive |
|
Purpose |
Designed for less-frequent data access but with quicker retrieval options. Suitable for backups, compliance, and disaster recovery. |
Aimed at long-term, low-cost data storage where retrieval is rare. Ideal for compliance, historical data, and infrequent backups. |
|
Retrieval Time |
Ranges from expedited (1–5 minutes) to bulk (5–12 hours).
|
Slower, typically 12 to 48 hours. |
|
Cost |
Lower than standard S3, higher than S3 Glacier Deep Archive. |
The lowest among S3 storage classes. |
|
Ideal For |
Scenarios where faster data retrieval might be required occasionally, like backup restoration or periodic data analysis. |
Archiving data for regulatory compliance or long-term retention with minimal access needs. Suitable for large volumes of data that don't need frequent retrieval. |
|
Which one to choose |
If you need more frequent or faster access to archived data, S3 Glacier might be more suitable.
|
If you're focused on cost savings and have low retrieval frequency requirements, S3 Glacier Deep Archive is the better choice.
|
How to use Amazon S3 Archive?
To set up Amazon S3 Archive, you need to create an Amazon S3 bucket and configure the storage class to Amazon S3 Glacier or Amazon S3 Glacier Deep Archive, depending on your archiving needs.
1. Choose the Objects > Upload > Add files button.
2. In the Properties section, select the S3 storage class you would like to upload your archive to.
* NOTE: Objects stored in many S3 storage classes have minimum object durations associated with them. In this case, uploading the test file to Glacier Deep Archive will result in 180 days of billing, even if it is deleted early. Storing 1 GB in S3 Glacier Deep Archive for 180 days with the retrieval is ~$0.03.
3. You will see the displayed details of the file’s upload status.
4. Once the file upload is complete, you'll see a summary showing whether the operation was successful or if it encountered an error. In this instance, the file uploaded successfully. Click the Close button to proceed.
How to Archive Your Data to Amazon S3
AOMEI Cyber Backup is a powerful and reliable enterprise-class backup software designed to protect critical data across a wide range of platforms and environments. It offers comprehensive data protection features, including system, disk, partition and file backups, ensuring fast recovery in case of data loss or corruption.
Integrating AOMEI Cyber Backup with Amazon S3 for archiving enhances data security and accessibility, and Amazon S3 provides a scalable and persistent storage solution that enables users to cost-effectively store large amounts of backup data. This integration not only makes it easy and straightforward to archive important data to Amazon S3, but also provides multiple layers of protection to ensure that data is backed up securely.
❈ Set up automated backup schedules (daily, weekly, monthly) to ensure your data is consistently backed up without manual intervention.
❈ Quickly connect your Amazon S3 account by entering your bucket name, access key, secret key, and region.
❈ Choose Amazon S3 as your primary backup destination for scalable, reliable, and cost-effective cloud storage.
❈ Restore your data promptly from Amazon S3 in case of data loss or corruption, ensuring minimal downtime and disruption.
❈ Select specific files, folders, or entire systems to restore, providing flexibility based on your recovery needs.
You can enjoy these features through downloading AOMEI Cyber Backup from the button below:
Archiving data to Amazon S3 with AOMEI Cyber Backup is a simple and straightforward process, follow the steps below to set up and manage your data archive with AOMEI Cyber Backup:
1. Click Target Storage > Amazon S3 > Add Target to open the add target page. Enter your Amazon S3 credentials including username, keyword, and bucket name, then click Confirm. Ensure you have the necessary permissions set up in your AWS account.

2. Click Backup Task > Create New Task to starting archiving your important data to Amazon S3. Select File Backup (for example) and choose files or folders for backup.
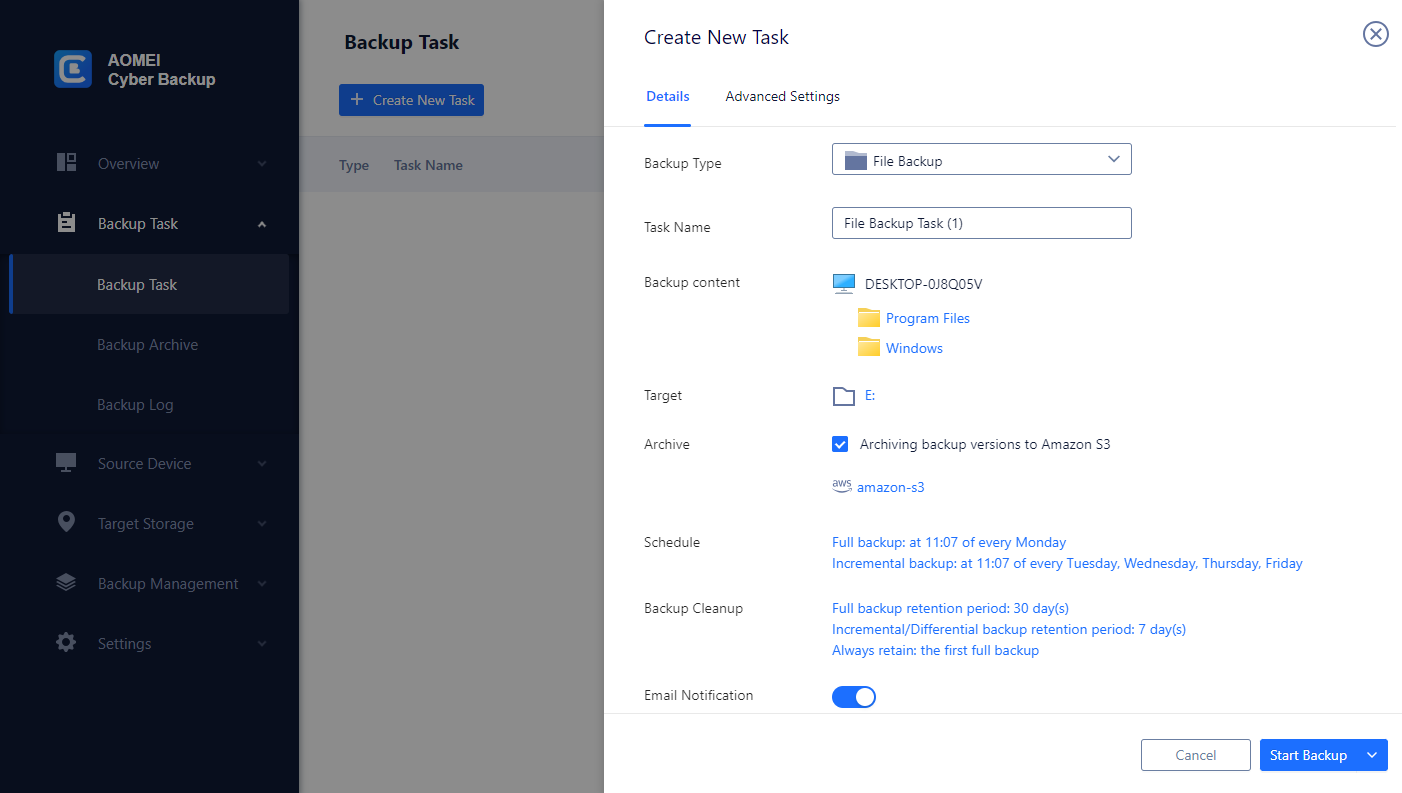
3. Check Archiving backup versions to Amazon S3 and click Select to choose the added Amazon S3. It will first create a backup locally or on the NAS and then upload the backup to Amazon S3. According to the3-2-1 backup rule, this ensures that the security of critical data and business continuity.
4. Schedule the backup task to run daily/weekly/monthly, and select backup retention policies to delete old backups automatically.
5. Click "Start Backup" to begin the backup process.
FAQ about Amazon S3 Archive
Q: How long does data retrieval take in Amazon S3 Archive?
A: Retrieval times for Amazon S3 Archive vary by storage class and retrieval option:
Amazon S3 Glacier Retrieval Times:
- Expedited Retrieval: Typically takes 1 to 5 minutes. This is ideal for urgent data access but comes with a higher cost.
- Standard Retrieval: Generally takes 3 to 5 hours. This option is suitable for regular data retrieval needs.
- Bulk Retrieval: Typically takes 5 to 12 hours. It's the most cost-effective option for retrieving large amounts of data.
Amazon S3 Glacier Deep Archive Retrieval Times:
- Standard Retrieval: Generally, takes 12 to 48 hours. This is the primary retrieval option for S3 Glacier Deep Archive.
- Bulk Retrieval: Usually takes 48 to 96 hours. This is the most economical option for retrieving large volumes of data over a longer period.
Q: Can I integrate Amazon S3 Archive with other AWS services?
A: Absolutely! You can integrate it with other storage classes in S3 and use AWS DataSync for seamless data transfer.
Q: What Amazon S3 Storage Classes include?
A: The S3 storage includes S3 Intelligent-Tiering, S3 Standard, S3 Express One Zone, S3 Standard-IA, S3 One Zone-IA, S3 Glacier Instant Retrieval, S3 Glacier Flexible Retrieval, S3 Glacier Deep Archive, and S3 Outposts.
Conclusion
You may encounter many challenges in using Amazon S3 Archive, but it can provide you with a powerful solution for long-term data storage, not only for individuals or businesses. After getting smart planning and management, its flexible retrieval features can bring you a variety of ideal options.

