




Block vs File Level Storage | Pros, Cons and Differences
Both block-level and file-level storage are popular among enterprises. Are you struggling to make a good choice between them? This article will provide you with a clear comparison of block vs file level storage.
By Crystal / Updated on March 8, 2023
Introduction: block vs file-level storage
Technology is always advancing. For the modern enterprises, there are 3 available architectures for storing and organizing data on devices – block-level, object-level, and file-level. Of these, file level and block level storage are the most common and popular ways to store and access data in on-premises, virtual, and cloud servers.
If you want to find a data storage way that suits your needs, then you may want to know how block level and file level storage work? And what is the difference between them? That’s what I’m going answer this in this article.

What is block-level storage
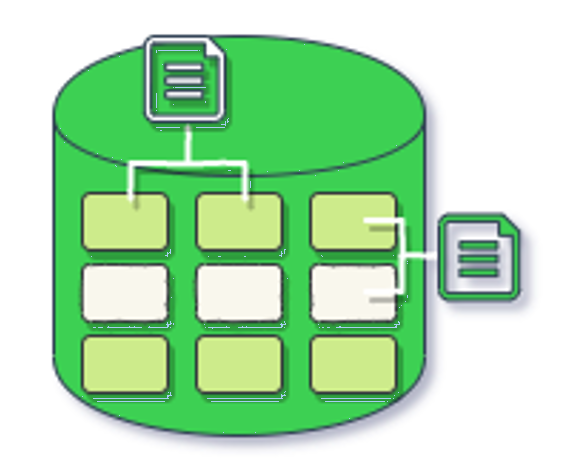
Block-level storage, or block storage, refers to the way that data is split into fixed blocks stored separately, with each block being assigned a unique hash value as a retrieval address. These blocks can be distributed across different environments or machines. For example, one block is in Windows and the rest in Linux.
These blocks can be stored anywhere in the system. When user retrieves a block, the storage system uses the unique identifier to reassemble the block into a file. This takes less time than navigating through directories and file hierarchies to access a file.
In addition, because of the complexity of block-level storage devices, enterprises usually use specialized backup features provided by third-party software to protect their workloads. For example, using AOMEI Cyber Backup - a free virtual machine backup software to perform image-level backups of virtual machines.
✤ Examples of block-level storage:
Block-level storage can be used for almost any kind of application. However, enterprises use it mainly for business-critical applications, transactional databases and virtual machines that require low latency.
Pros
- Efficient use of storage space.
- Fast retrieval.
- High performance with low latency.
- Low fail rate.
- Highly flexible.
Cons
- High cost.
- Lack of metadata.
- Not searchable.
- Performance upgrades can be challenging.
What is file-level storage
File-level storage, or file storage, refers to the way of storing data in a hierarchical architecture. Data and its metadata are stored in folders/files forms under a hierarchy of directories and subdirectories. To locate a file, the computer system needs the path from directory to subdirectory to folder to file.
In file-level storage system, the SBM (Server Block Message), CIFS (Common Internet File System), or NFS (Network File System) protocol is used for storage, and provides centralized and simple accesses. Therefore, File-level storage is suitable for bulk storage of files and accesses.
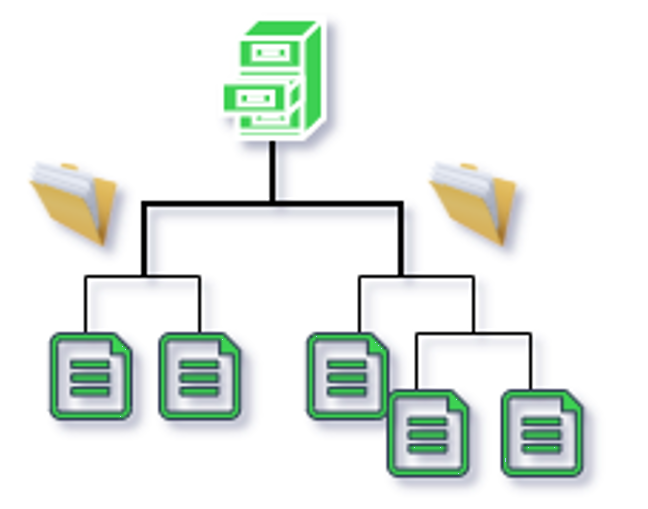
✤ Examples of file-level storage:
File-level storage is commonly used on computer hard drives or Network Attached Storage (NAS) devices.
Pros
- Low cost.
- Familiar to most users.
- Easy to access on a small scale.
- Users can manage their own files.
- Allows access rights/file sharing/file locking to be set at user level.
Cons
- Low performance.
- Challenging to manage and retrieve large numbers of files.
- Hard to work with unstructured data.
- Becomes expensive at large scales.
What is the difference between block-level and file-level storage
Read this far, you have already known the pros and cons of block-level and file-level storage. But to make a good choice from block vs file level storage, you may need a clear comparison. Here is a table showing the difference between block-level and file-level storage.
| Block-level storage | File-level storage | |
| Kind of storage system | Split data into blocks and store separately | Centralized file storage |
| Deployed for | Storage Area Networks (SAN) | Network Attached Storage (NAS) |
| Complexity | Complex | Simple |
| Flexibility | More flexible | Less flexible |
| Retrievability | Fast retrieval | Easier to access |
| Performance | Higher | Lower |
| Cost | Higher | Lower |
| File sharing | Requires access permissions | Requires installation of an OS |
How to choose from block-level and file-level storage
All comparisons are made to make a better choice. However, there is no right or wrong storage option, only the one that best meets your current needs.
For example, if you are a developer, you may need a high-performance storage device for computing situations that require fast, efficient and reliable data transfer, then block-level storage can be a good choice. But if you don’t have these needs, then file-level storage will be more cost effective and easier to manage.
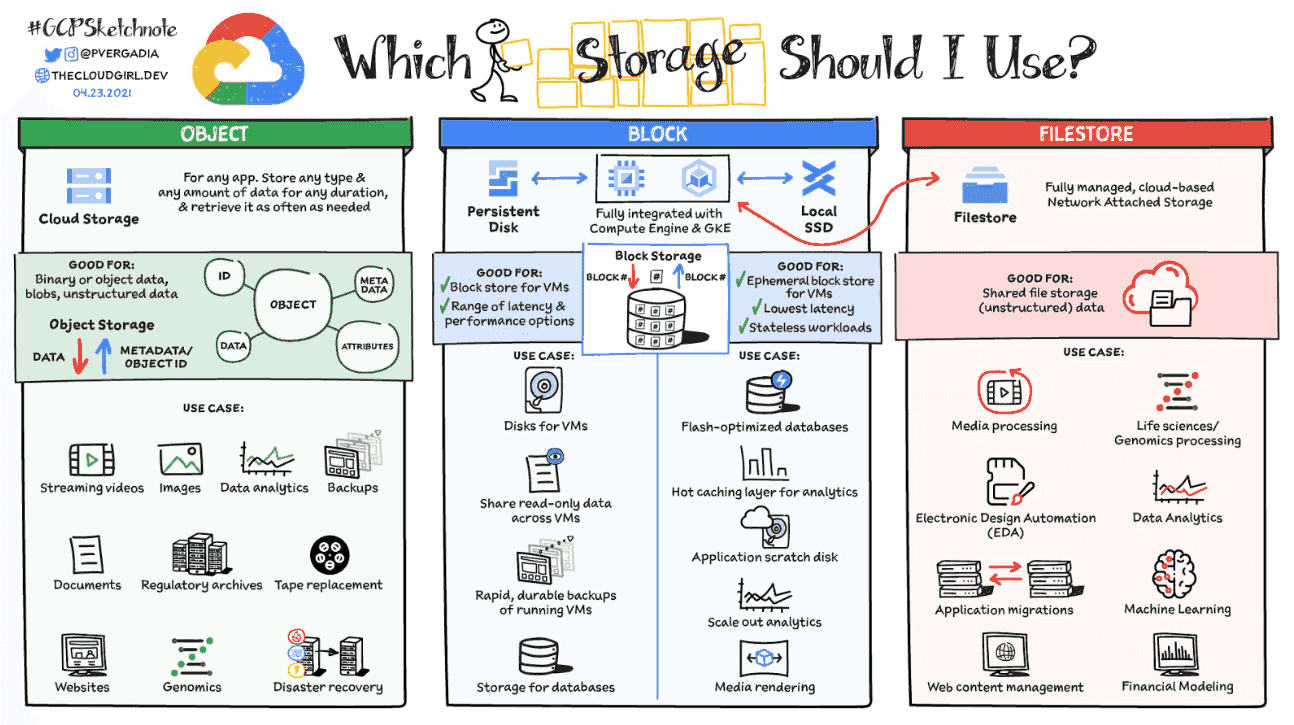
You can evaluate which storage is better for you based on the following:
- Volume: Organizations with high volumes of data tend to choose block-level storage rather than file-level storage.
- Cost: File-level storage is cost effective at small scales, but becomes expensive at large scales.
- Management ease: Block-level storage is suitable for managing large volumes of data, while file-level storage is easier in managing lower volumes of data.
- Retrievability: Block-level storage is a common fast way for business-critical data retrieval. But file-level storage is easier to operate.
- Handling of metadata: Block-level storage does not contain metadata.
- …
Summary
What is the future of storage? As the rapid growth of data volumes in the information age, storage technologies and devices are keep evolving, and more new types of data and storage are likely to emerge.
As for organizations, it is important to continually evaluate and optimize the type of storage for business data as business needs change. In this article I introduced the pros, cons and differences of block vs file-level storage. Hope it could be helpful to you.

